
|
|
Acquisition automatique de Connaissances
|
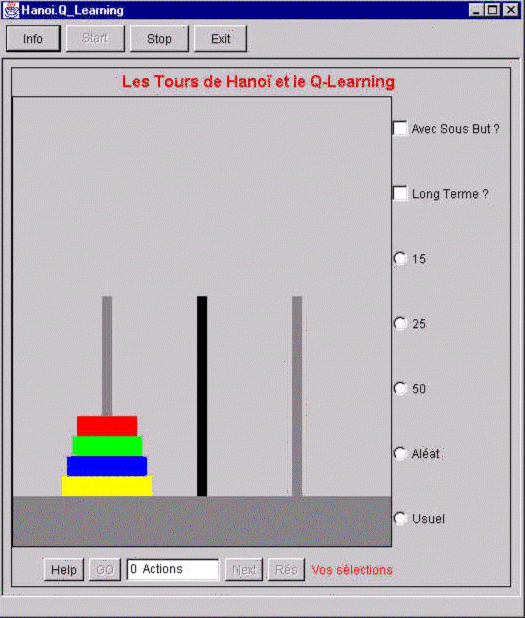
Si votre système de navigation vous permet de voir (attendre le chargement et le lancement de Java platform) cette applet ?
("If you don't see the applet running, you need to install Java Plug-in, which happens automatically when you install the J2SE JRE or SDK. We strongly recommend that you install the latest version; at least 1.3.1 is required for all SUN applets. You can find more information in the
Java Plug-in home page.")
Alors vous pourrez visualiser l'applet Q-Learning Tours Hanoi
C’est un problème souvent donné en exemple lors de l’apprentissage de Prolog : c’est un problème récursif de représentation simple, dont la solution peut être trouvée en 2n–1 mouvements, n étant le nombre de disques. La connaissance de la longueur optimale permet de tester l’apprentissage. Le nombre d'états est N = 3n + 1 (3 buts possibles).
| Pour passer de l’état : | 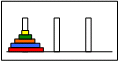 |
à l’état : |  |
Il faut passer par l’état : | 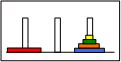 |

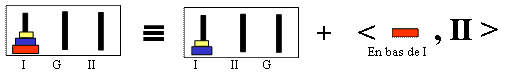
Un disque : son diamètre = son numéro de 1 à n en commençant par le plus petit;
Un état : un vecteur de 3 piles de disques, le but est le numéro de l'une d'entre elles ;
Un but : le numéro de la pile où doivent être placés les disques ;
Un mouvement autorisé : un état initial, le n° ND du disque déplacé, la pile de triplets <n°disque / n°pile en bas de laquelle il était placé / but = le n° de pile but> mémorisés, l'état final ou simplement le n° de la pile destination (cette alternative sera examinée ultérieurement) ;
Placement d'un sous-but : un mouvement autorisé particulier qui affecte la pile de triplets mémorisés : le disque déplacé est "effacé" entre l'état initial et l'état final et ce placement ajoute un triplet <n° disque / n°pile / but> ;
Effacement d'un sous but : mouvement inverse.
| Soit l'État Initial |  |
et le But habituel |  |
| On 'oublie' le plus grand disque |  |
On est en présence d'un des états du jeu avec 3 disques

On retrouve un état du jeu avec 3 disques en "oubliant" le disque n et en plaçant un sous but sur la même pile.

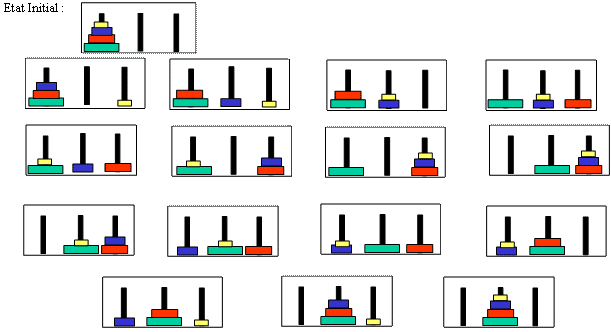
L'exercice concernant l'application des techniques d'apprentissage par renforcement au problème des Tours de Hanoï semble adresser les sujets suivants :
On pourrait ainsi comparer les résultats avec le problème avec 4 disques entre apprentissage simple ou à l'aide de sous-buts.
|
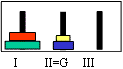 |
État initial (cf. état ci-dessus),
Pile de buts := Pile de buts + <n°disque:=4/n°pile=I/but:=II>
Disque déplacé:= 4
N° de la pile destination := 0 (il faut programmer le changement de taille du problème et le changement éventuel de but)
Si le disque n° = n = dimension du problème est sur une pile n°X =/= n° pile but = Y, il faut placer le sous-but en Z,
Si ce disque est déjà sur la pile but il faut placer le sous-but sur cette même pile.
Les deux piles non-but jouent un rôle équivalent tant qu'on n'introduit pas de gestion de sous-but. Aujourd'hui je suis tenté de ne pas tenir compte des symétries.
Le programme indique au système quel est le but à atteindre et ce système doit apprendre par une succession d'essais/erreurs comment atteindre ce but. Le système est connecté à son environnement par des perceptions et des actions. A chaque interaction, l'agent reçoit une information relative à son état courant s, il choisit et effectue une action a qui le fait passer dans un état s', et il reçoit un signal de renforcement.
La politique p : S -> A : application des états dans les actions;
La récompense immédiate r : S x A -> [0, 1] indicateur immédiat de la qualité
d'une action dans un état s ;
"Les conséquences futures d'une action ne
sont pas incluses dans le renforcement reçu, mais peuvent
avoir une influence non négligeable sur l'ensemble des
interactions."
On cherche à optimiser l'espérance des
récompenses à 'horizon fini' ou à 'horizon
infini'.
La fonction valeur indicateur de la valeur du choix à long terme
"On peut calculer la valeur d'une action dans un état s suivant
une politique p, quantité notée
Qp(s, a) comme l'espérance
en partant de l'état s et choisissant l'action a puis en
suivant la politique p."
Le Q-Learning a été développé "afin de déterminer une politique optimale p* sans disposer de toutes les données".
Pour
chaque couple <s,a> initialiser le vecteur Q(s, a) à 0;
t:= 0; s0 := état initial;
Répéter
Exit quand st est un état terminal
Choisir une action at dans A(st) //Explore vs Exploite
Exécuter at
Q(st,at) := (1 - a) * Q(st,at)
+ a(r(st,at) + g * Max Q(st+1,at+1)); // Max = max sur at+1 Î A(st+1)
t := t+1;
End Répéter
a est un taux de changement et g est un taux d'interet
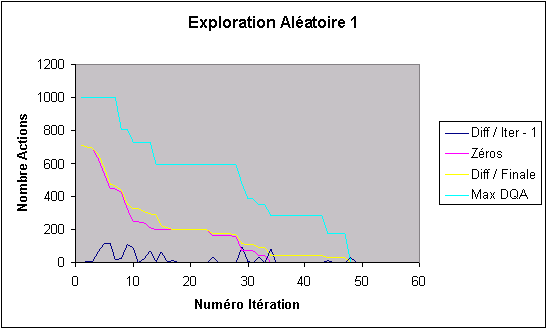
Courbe donnant le nombre d'actions dont la valeur est différente de celle qu'elle avait à l'itération précédante.

La longueur du chemin optimal est égale à 2n-1, donc égale à 15 pour n = 4. Le nombre d'itérations d'exploration pour 4 disques doit donc être supérieur à 15.
Les deux figures suivantes correspondent aux résultats de deux lancements de 50 itérations d'exploration effectuées chacune avec chacun des trois buts, les 4 disques étant tous placés sur une pile choisie aléatoirement. Pour les deux courbes ci-dessous :

Le problème des Tours de Hanoi est un bon exemple pour l'Apprentissage par Renforcement, ses caractéristiques correspondent aux réponses à la question principale :
Quand doit-on faire appel à l'apprentissage par renforcement ? (tâche en plusieurs étapes, la récompense ne vient qu'à la fin d'une succession de choix, …)
Pour l'apprentissage sans gestion de sous-but, l'algorithme Q-Learning permettant d'apprendre la fonction d'utilité liée aux actions a été utilisé. C'est un algorithme très simple.
La notion d'apprentissage à long terme a pu être testée. Il est facile d'enregistrer les résultats d'une phase d'exploration.
Elle a été implémentée par programmation : Pour chaque état du problème avec 4 disques (la généralisation à n disques ne poserait aucun problème particulier), une action qui permet de passer au problème avec 3 disques avec nouveau but est définie dans le code de l'exécution de l'action. Le logiciel utilise alors les résultats de l'apprentissage du problème avec 3 disques pour atteindre le sous-but.
| L'objectif de ce site est de décrire simplement (clairement autant que faire se peut) les différentes techniques de Représentation des Connaissances et leur utilisation dans les domaines de la Gestion des Connaissances et de l'Intelligence Économique. N'hésitez pas à nous contacter pour proposer un simple échange de liens ou la diffusion d'un texte pédagogique sur une de ces techniques. |
| OCSIMA > Connaissances > Apprentissage Q-Learning |  |
Plan Conseil Études Partenaires |
| LAURENT Jean-Marc - Conseil Gestion des Connaissances - OCSIMA - Consultant Knowledge Management | |||
|
|
Pour nous écrire, cliquez ici : | ||