|
|
Case Based Reasoning (and Analogical Reasoning) - Définition(s) |
|
| LAURENT Jean-Marc - Méthode OCSIMA | Audit - Conseil - Développement - Formation | |
|
|
|
Il est maintenant admis que le principal goulet d’étranglement rencontré lors du développement d’un système à base de connaissance, représentée sous la forme de règles de production, réside dans l’élucidation de cette connaissance, malgré l’aspect déclaratif "en langage naturel" de ces règles, avantage souvent mis en avant pour ces dernières, et bien que plusieurs méthodes aient été proposées (KADS, KOD, …). Peu de choses ont été écrites sur ce sujet dans le domaine du Raisonnement Basé sur les Cas (Case Based Reasoning), la principale raison étant que, parmi les promoteurs de cette technique de raisonnement, certains ont été jusqu'à considérer que l’étape de l’analyse de la connaissance n’était pas nécessaire, l’expert s’exprimant "naturellement", d’après eux, en terme de cas, cas qu'il suffirait simplement de recenser. En fait certaines questions demeurent sans réponse. Il est assez facile de répondre aux questions suivantes: Etant donnés le domaine et la tâche de l’application,
Les réponses à ces questions permettent de définir précisément la tâche à accomplir lors de la collecte de la Base de Cas (BC): Que doit-on collecter ? Par contre, mises à part quelques présentations d’heuristiques exprimant simplement des règles de bon sens, peu de réponses ont été proposées pour les deux questions fondamentales suivantes:
Le propos ici est d’étudier s’il est possible de transposer une méthode issue du génie logiciel orienté objet, et en quoi cette transposition permettrait d’atteindre une "bonne couverture" du domaine par la base de cas recensés. En introduction il est présenté un rappel de définitions liminaires, des structures de données et des résumés des algorithmes tels qu'ils avaient été implémentés dans la méthodologie DiaBC (Diagnostic Basé sur les Cas) en 1992. Ensuite des réponses aux premières questions simples sont proposées. Finalement, une méthode est préconisée pour le recensement d’une base de cas, méthode correspondant à une transposition de la méthode OOSE (Object Oriented Software Engineering) de Ivar Jacobson [JAC, 93]. I.1 Rappels et DéfinitionsLe Raisonnement par Analogie (RA) et le Raisonnement Basé sur les Cas (RBC) sont deux approches utilisant des solutions de problèmes résolus antérieurement. Ce sont des procédés dont le but est d’élaborer la solution d’un nouveau problème (le problème cible) en:
La mesure de similitude dépend des correspondances individuelles entre les parties, caractéristiques ou aspects de la base et de la cible. Le RBC, manipulant des cas relatifs à un seul et même domaine, est souvent considéré comme une forme plus restreinte du RA, ce dernier se caractérisant par des applications inter domaines: l’exemple en général cité est celui de la recherche de la solution d’un problème médical à partir de la solution d’un problème militaire analogue [DUN, 45]. La première implémentation du RA remonte au programme d’Evans [EVA, 68] en 1968, programme résolvant des tests d’intelligence basés sur des analogies entre figures géométriques. Mais l’une des premières descriptions exhaustives des différentes étapes du processus n’a été publiée qu’en 1989-90 par Campbell et Wolstencroft [WOL, 89] [CAM, 90]. Les 7 étapes qu'ils ont identifiées sont les suivantes (cf.fig. 1):
fig1: Les 7 étapes du raisonnement par analogie d’après Campbell et Wolstencroft. |
I.2.A Les Paramètres et les SymptômesUn paramètre est une caractéristique ou indicateur mesurable de la réponse ou sortie du système. Un symptôme est un couple <paramètre, valeur ou tendance hors norme>. A un même paramètre il peut donc correspondre plusieurs symptômes. Selon le Robert on peut distinguer plusieurs types de symptômes: "les symptômes subjectifs perçus et signalés par le patient, les symptômes objectifs, découverts par le médecin, et les symptômes diacritiques, liés d’une façon sûre à une maladie déterminée, qu’ils permettent de diagnostiquer". Cette distinction est reprise dans l’implémentation informatique de la méthodologie DiaBC, une distinction étant faite entre :
I.2.B Les CasUn cas (déjà rencontré ou simulé) est une entité ou objet, manipulé dans son intégralité. Les principaux champs d'un cas de diagnostic / thérapie sont les suivants:
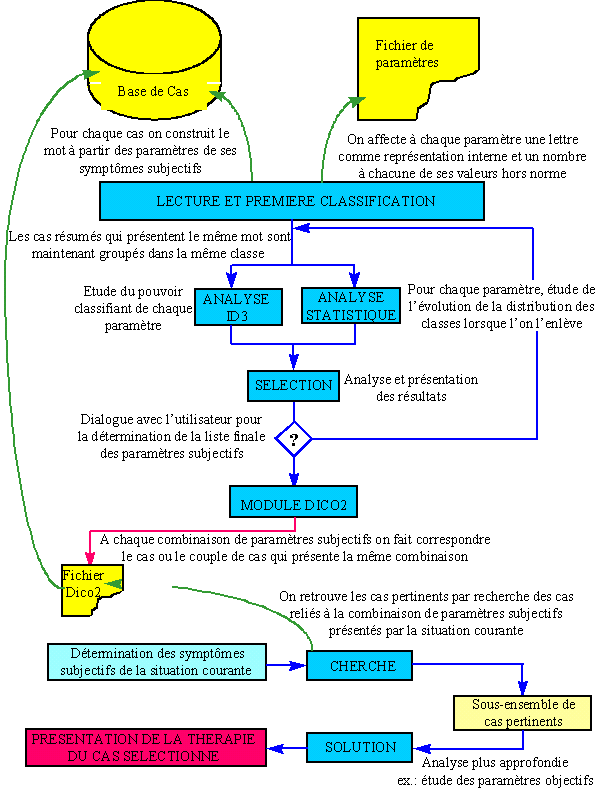
À la place de sa fonction action, un cas peut contenir une liste de sous-cas. Ceux-ci ont la même structure que les cas, mais c'est au niveau de leur liste d'index que l'on peut placer les symptômes objectifs et/ou diacritiques, le diagnostic nécessitant un examen plus approfondi. Les paramètres sont également des objets contenant, outre leur nom, leur valeur normale, leurs valeurs hors norme (exprimées éventuellement sous la forme d'ensembles flous), celles qui peuvent s'annuler ou s'ajouter, permettant la détection des cooccurrences de dysfonctionnements. On peut également spécifier, au niveau du cas, un degré de nécessité de présence ou un délai d'apparition (également exprimé éventuellement sous la forme d'un ensemble flou) pour chacun des symptômes. I.2.C Les Principaux AlgorithmesLes algorithmes sont répartis en deux groupes: le groupe pré-diagnostic, algorithmes qui ne doivent être exécutés que lors de la création de la base de cas ou lors d'une modification profonde de celle-ci, et le groupe diagnostic/thérapie. Lors de la phase de pré-diagnostic des dictionnaires de similitude vont être créés, dictionnaires composés de toutes les combinaisons possibles des représentations internes des paramètres correspondant aux symptômes subjectifs. Aussi, afin d'éviter toute explosion combinatoire, il est nécessaire de minimiser le nombre de ces paramètres. Ceci est réalisé à l'aide d'un premier algorithme du type ID3 qui va déterminer leur "pouvoir classifiant": il est inutile de conserver un paramètre qui apparaît dans presque tous les cas ou au contraire dans presque aucun cas (un tel paramètre n'est que peu discriminatoire et ne sera que peu utile pour la recherche de cas). Un deuxième algorithme va étudier l'évolution de la répartition statistique de la base de cas (les cas présentant la même combinaison de représentations internes de paramètres sont regroupés dans un même ensemble, une classe statistique, dans un premier dictionnaire dico1) lorsque l'on enlève un de ces paramètres. Le dictionnaire principal (dico2) est alors initialisé par la liste de toutes les combinaisons possibles des représentations internes (une lettre) des paramètres restants. Pour chaque combinaison, des liens sont établis avec les cas ou couples de cas suivants:
Le diagnostic en lui même est composé des étapes suivantes:
fig2. Les modules de la méthodologie DiaBC |
|
|
Dernière révision janvier 06 |
Plan du site OCSIMA |
Pour nous écrire, cliquez ici : |