|
|
Case Based Reasoning : Recensement des Cas |
|
| LAURENT Jean-Marc - Méthode OCSIMA | Audit - Conseil - Développement - Formation | |
|
|
|
III.1 Des exemples de ce que l'on peut lire dans la littérature
"This can be done along the physical components involved in the overall domain task. The task-structure may reflect the structure of the physical components that occur in planning or design. Another way of factoring an overall task into sub-tasks is by focusing on reoccurring problems that are separated from other problems by having unique input or output". La première méthode proposée ne peut être appliquée, comme nous le répéterons plus loin, que lorsque le nombre de composants est faible. La deuxième méthode est un meilleur point de départ, mais n'est pas assez développée: ils rappellent simplement plus loin dans leur texte l'existence des techniques d'élucidation de la connaissance.
"There are several advantages of the CBR approach : représente un escamotage du problème réel.
"Knowledge acquisition for a case based system is natural." Si cette affirmation semble assez proche de la réalité par exemple dans le domaine du diagnostic médical (un médecin va assez "naturellement" évoquer le cas d'un patient avec un confrère), elle paraît un peu trop optimiste pour de nombreux autres domaines non analytiques (ex.: les architectes ne s'expriment pas naturellement en terme de cas). Bien que dans cet article figure un paragraphe ayant pour titre "Collecting Cases: How ?", les conseils sont plutôt axés sur la question "Comment collecter un "bon" cas ?" III.2 Les recensements simples : exemple du diagnosticIII.2.A Décomposition hiérarchique du systèmeL'opération de diagnostic [CHA, 83] consiste en l'identification d'une description (partielle) d'une situation avec un noeud spécifique de la hiérarchie représentant le système diagnostiqué: les niveaux les plus élevés de cette hiérarchie correspondent aux concepts les plus généraux (niveau fonctionnel), les niveaux spécifiques (niveau des composants) se trouvant à la partie inférieure. Le raisonnement affine progressivement le problème posé par une analyse globalement top-down pour déterminer où se situe dans la hiérarchie le dysfonctionnement, origine des symptômes observés. Partant de cette définition, il est possible de décomposer le système selon plusieurs niveaux d'abstraction, la plupart des cas seront recensés au niveau le plus bas, les niveaux supérieurs correspondront aux dysfonctionnements qui font intervenir plusieurs composants élémentaires, ou auxquels il est difficile d'attribuer un composant précis. III.2.B Utilisation d'un réseau causalUn diagnostic peut également être établi grâce à un modèle causal décrivant les possibilités de comportement anormal du système sous contrôle. Console & al [CON, 91] décrivent une approche "focusing (model based) diagnosis". L'opération de diagnostic est composée de deux processus :
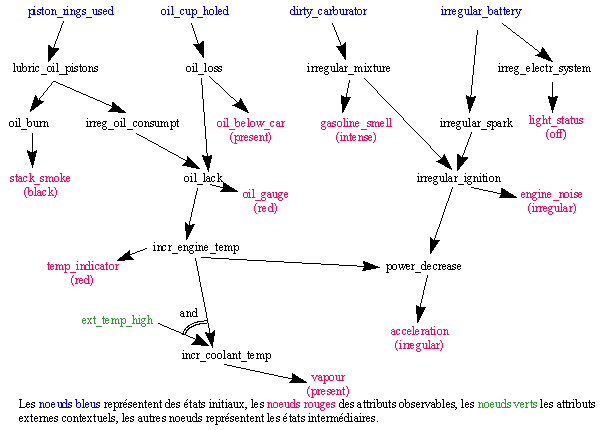
fig3. d'après Console et al Les auteurs proposent de compiler le réseau causal afin de déterminer pour chaque noeud du réseau l'ensemble de ses conditions nécessaires (l'ensemble des observations nécessaires pour que le noeud corresponde au dysfonctionnement courant). Cet ensemble de conditions nécessaires permet d'éviter l'étude de branches d'alternatives. Par exemple pour le noeud "incr_engine_temp" cet ensemble sera : temp_indicator (red) & acceleration (irregular) & [vapour (present) V not ext_temp_high] & oil-gauge (red) & [oil_below_car (present) V stack_smoke (black)] En prolongeant cette compilation, on aboutit à quatre cas représentant l'ensemble du réseau causal de la figure 3 :
III.3 Critique de ces SolutionsOn constate que les différentes méthodes proposées pour le recensement des cas tentent de partir de deux points distincts :
La démarche consistant à identifier les cas après énumération des composants peut paraître plus rassurante dans la mesure où elle semble aboutir à une collection de cas présentant une meilleure couverture du domaine (il semble aisé d'identifier tous les composants susceptibles d'être défectueux). Mais elle présente deux défauts principaux :
En fait le montage représenté par la figure 4a n'assure pas un fonctionnement correct du régulateur R (placé avant le transformateur, il fonctionne sous 220V et sous trop faible intensité). Le montage correct est représenté par la figure 4b. Aussi, sans qu'aucun des composants ne soit (statiquement) défectueux, on aboutit avec le montage de la figure 4a à une mauvaise régulation de la lumière (dysfonctionnement dynamique et de contrôle) et le transformateur bourdonne jusqu'à ce qu'il "claque". A ce moment on sera en présence d'un dysfonctionnement statique. Ce problème semble simple à résoudre parce que seuls les câbles dédiés à la fonction de régulation ont été représentés. Il n'en est pas du tout de même lorsque tous les câbles assurant les différentes fonctions sont rassemblés et plus ou moins enchevêtrés.
Il semble donc souhaitable de suivre l'approche par décomposition fonctionnelle en sous tâches. Mais d'une part l'identification des composants demeure nécessaire, d'autre part aucun conseil méthodique n'est présenté dans la littérature concernant cette approche par décomposition. ConclusionIl serait souhaitable de disposer d'une méthode permettant une analyse décomposée en trois parties :
III.4 Pourquoi la Méthode OOSE de Jacobson ?III.4.A Pourquoi une Méthode de Génie Logiciel ?Trois principales raisons ont amené à considérer l'intérêt des techniques du génie logiciel pour l'analyse d'un domaine en vue du recensement d'une base de cas :
On pourrait dire que dans le domaine du diagnostic, on souhaite recenser les dysfonctionnements, alors que ce n'est pas la fonction première d'une analyse classique d'un logiciel. Il est facile de répondre qu'une bonne analyse doit identifier les exceptions, celles-ci n'étant rien d'autre que des fonctionnements anormaux du système. III.4.B Pourquoi une Méthode Objet ?Les principales origines de l'approche objet sont au nombre de quatre :
C'est cette dernière origine qui a tout naturellement conduit à étudier les approches objet pour l'analyse des systèmes RBC. Parallélisme entre Cas et ObjetIl existe en effet un parallélisme certain entre la composition d'un cas et la définition d'un objet telle que présentée par Bouché [BOU, 94], suivant le courant de pensée de Booch :
Finalement, un "bon cas" doit satisfaire aux mêmes contraintes ou critères que ceux auxquels doit satisfaire un "bon objet", notamment en terme de maintenance :
Le cas est à la représentation des connaissances ce qu'est l'objet aux langages de programmation. Un cas est une entité qui reste indépendante des autres cas. La lisibilité est meilleure et du fait de cette indépendance, la maintenance est facilitée. L'Analyse Orientée ObjetLes raisons précédentes sont des raisons qui nous font préférer une représentation des cas par des objets, une analyse de la base de cas en suivant une méthode objet. Mais ici le premier objectif est d'analyser le système (sous contrôle, de conception, de planning, etc.) pour pouvoir recenser la base de cas, et non d'analyser la base de cas. Bouché [BOU, 94] situe cette étape: "l'analyse permet de modeler un environnement en identifiant les classes et objets du vocabulaire du domaine du problème" et rappelle une suggestion de Shlaer et Mellor pour l'identification des classes et objets: "les choses tangibles, les rôles, les événements, les interactions". Un objet doit posséder, suivant la définition présentée ci-dessus, un état et un comportement. Ainsi on retrouve les souhaits exprimés plus haut à savoir une analyse statique et dynamique. Et surtout l'approche objet permet une grande cohérence entre les objets et leur dynamique, contrairement à l'approche systémique classique où l'on modélise séparément les données et les traitements, séparation risquant d'introduire des incohérences, des accès concurrents aux données, etc. III.4.C Pourquoi la Méthode OOSE d'Ivar Jacobson ?Comme le reconnaît Bouzeghoub [BOUZ, 94], OOSE est une méthode objet originale, dont le cycle de développement est l'un des plus complets. Elle suit une démarche à la fois structurée et systémique tout en intégrant l'approche objet. Ses deux principales caractéristiques et avantages sont :
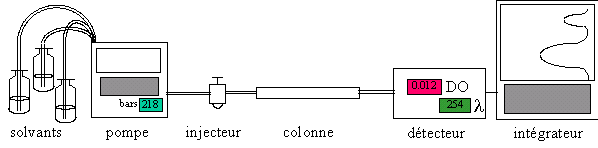
On constate immédiatement que ces deux caractéristiques, présentées comme des avantages, satisfont pleinement les souhaits formulés en conclusion du paragraphe précédent. III.4.D La Méthode OOSEDescription de l'exempleUne analyse chromatographique en phase liquide repose sur le principe suivant: les composés chimiques d'un mélange, mélange introduit dans le système à l'aide d'un injecteur, sont plus ou moins retenus par une phase stationnaire solide (contenue dans une colonne) lorsqu'ils sont entraînés par un mélange de solvants, mélange poussé par une pompe haute pression. En sortie de colonne, ils seront détectés les uns après les autres, et la surface de chaque pic (calculée par un intégrateur) du chromatogramme résultat est proportionnelle à leur concentration dans le mélange. Il est ainsi possible de déterminer la composition inconnue d'un mélange donné de composés en comparant les surfaces de ses pics à celles obtenues avec un mélange de composition connue. Le schéma de principe du système est représenté figure 5.
fig. 5 Schéma de principe d'un système d'analyse chromatographique en phase liquide La Phase d'Analyse de OOSECette phase construit deux modèles: le modèle des besoins et le modèle d'analyse (remarque: dans tout ce paragraphe, le terme système fait référence au système sous contrôle, de conception, ou de planning et non au système RBC, sauf expressément stipulé) Le Modèle des BesoinsJacobson indique que ce modèle doit préciser les acteurs, les cas d'utilisation, les interfaces et les objets du domaine. Les acteursJacobson fait une distinction entre un utilisateur (instance d'une personne) et un acteur (instance du rôle que cet utilisateur joue). Cette distinction n'est pas nécessaire pour le recensement de la BC, les deux notions seront regroupées sous le terme d'utilisateur. Il en sera de même pour la distinction entre acteurs primaire (utilisateur direct du système) et secondaire (superviseur du système). Ces simplifications sont la conséquence du fait qu'une base de cas est dédiée à un type d'utilisateur précis. Les cas d'utilisationUn cas d'utilisation est une manière spécifique d'utiliser le système en faisant appel à une partie de sa fonctionnalité. Les utilisateurs du système étant identifiés, il est facile de recenser les cas d'utilisation, les questions suivantes proposées par Jacobson pouvant servir de guide :
Les interfacesUne interface utilisateur reflète le point de vue logique de l'utilisateur sur le système. Mais il faut aussi identifier les interfaces entre sous-systèmes, opération plus complexe: certaines s'avéreront peut-être inutiles, mais dans ce cas les deux sous-systèmes devront être considérés comme un seul, au contraire un sous-système pourra être décomposé et une interface ajoutée. Les objets du domaineLeur identification et définition permet les dialogues avec l'expert et les utilisateurs. L'objectif ici est de simplement constituer un dictionnaire des concepts du domaine. Dans le cas d'une application complexe et/ou importante, l'analyste doit en effet tout d'abord acquérir une connaissance et une expérience du domaine:
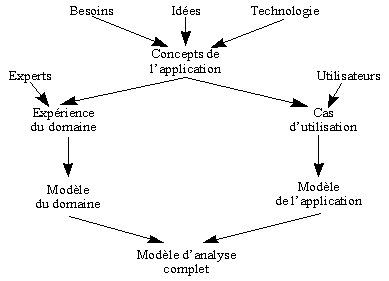
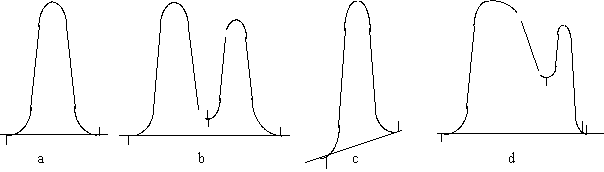
fig. 6 L'élaboration du Modèle d'analyse d'après Rumbaugh [RUM, 94] Le Modèle d'AnalyseLe modèle d'analyse structure le modèle des besoins en trois types d'objets: les objets interfaces, les objets entités et les objets de contrôle. Durant cette phase les comportements décrits dans les cas d'utilisation sont répartis entre ces trois types d'objets. Remarque : La phase d'analyse de OOSE doit recenser les objets au sens langage informatique. Dans la phase d'analyse du système (domaine du diagnostic, de la conception, du planning, etc.) on veut recenser les objets au sens composants, matériels ou logiciels, et déterminer leur rôle (interface, contrôle, liaisons statique ou dynamique). Cette confusion concernant les deux significations du concept d'objet est volontairement maintenue. Le soin d'identifier le sens qu'il faut donner au mot "objet" est laissé au lecteur, afin de maintenir le parallélisme entre les deux phases d'analyse. Les Objets InterfacesLe rôle des objets interfaces utilisateur est de traduire les actions d'un utilisateur en événements dans le système et d'informer l'utilisateur des événements du système qu'il doit connaître. Le chromatogramme résultat est un objet interface, constitué de ("constitué de" est une liaison statique) pics, autres objets interfaces. La forme de ceux-ci constitue un paramètre subjectif (pic symétrique fig. 7a, ou présentant une traînée fig. 7d).
fig. 7 Différentes configurations de pics Le rôle des objets interfaces entre sous-systèmes est souvent plus complexe: par exemple le détecteur envoie un signal continu à l'intégrateur. L'objet interface entre eux doit échantillonner le signal et transmettre ces données discrètes à un objet de contrôle. N.B : On s'aperçoit que les objets interfaces permettent d'identifier les paramètres subjectifs. Les Objets EntitésIls sont destinés à modéliser l'information que le système traite, et le comportement naturellement associé à cette information. Par exemple le calculateur de surface de pic est un objet entité. N.B.: Ils permettent d'identifier les composants et les liaisons statiques. Les Objets de ContrôleIls sont destinés à recevoir les comportements qui ne seraient pas naturellement associés aux deux autres types d'objets. Typiquement ces comportements sont du type transaction, ou cloisonnement entre les objets interfaces et les objets entités. Par exemple l'objet de contrôle entre l'interface et le calculateur de surface de pics : ce dernier doit actionner une alarme lorsque la pente de la ligne de base, calculée à partir des données transmises par l'interface, a dépassé en augmentant un certain seuil depuis un certain temps (début de pic), est passé en dessous d'un certain seuil depuis un certain temps (fin de pic) ou a changé de sens (sommet du pic ou début d'un pic non séparé du précédent). Sur la figure 7 les débuts de pic sont indiqués par l'intégrateur par un petit trait vertical vers le bas, les fins de pic par un petit trait vertical montant; ces marques fonctionnent comme des parenthèses imbriquées. Cet objet de contrôle utilise deux paramètres principaux pour détecter les débuts et fins de pic :
L'observation des marques de début et de fin de pic permet de vérifier si ces paramètres ont bien reçu des valeurs correctes, ou si ces valeurs doivent être modifiées.
N.B.: Les objets de contrôle permettent d'identifier les liaisons dynamiques entre objets. III.4.E Rappel: Les Techniques d’interviewCes techniques doivent être employées de la même manière qu'elles le sont pour l'acquisition des connaissances. Cette étape nécessite de la part de l'analyste psychologie et pédagogie, une préparation appropriée, un enregistrement et une documentation des données (verbales, graphiques, observées, qualitatives et quantitatives), et demeure un processus plus complexe qu'un "bon" ordonnancement de "bonnes" questions. Comme indiqué plus haut, l'analyste doit tout d'abord acquérir une bonne connaissance des concepts du domaine, il pourra ensuite s'aider des schémas suivants:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
Dernière révision janvier 06 |
Plan du site OCSIMA |
Pour nous écrire, cliquez ici : |